
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Google DeepMind and Hugging Face have just released SynthID Text, a tool for marking and detecting text generated by large language models (LLMs). SynthID Text encodes a watermark into AI-generated text in a way that helps determine if a specific LLM produced it. More importantly, it does so without modifying how the underlying LLM works or reducing the quality of the generated text.
The technique behind SynthID Text was developed by researchers at DeepMind and presented in a paper published in Nature on Oct. 23. An implementation of SynthID Text has been added to Hugging Face’s Transformers library, which is used to create LLM-based applications. It is worth noting that SynthID is not meant to detect any text generated by an LLM. It is designed to watermark the output for a specific LLM.
Using SynthID does not require retraining the underlying LLM. It uses a set of parameters that can configure the balance between watermarking strength and response preservation. An enterprise that uses LLMs can have different watermarking configurations for different models. These configurations should be stored securely and privately to avoid being replicated by others.
For each watermarking configuration, you must train a classifier model that takes in a text sequence and determines whether it contains the model’s watermark or not. Watermark detectors can be trained with a few thousand examples of normal text and responses that have been watermarked with the specified configuration.
We’ve open sourced @GoogleDeepMind‘s SynthID, a tool that allows model creators to embed and detect watermarks in text outputs from their own LLMs. More details published in @Nature today: https://t.co/5Q6QGRvD3G
— Sundar Pichai (@sundarpichai) October 23, 2024
How SynthID Text works
Watermarking is an active area of research, especially with the rise and adoption of LLMs in different fields and applications. Companies and institutions are looking for ways to detect AI-generated text to prevent mass misinformation campaigns, moderate AI-generated content, and prevent the use of AI tools in education.
Various techniques exist for watermarking LLM-generated text, each with limitations. Some require collecting and storing sensitive information, while others require computationally expensive processing after the model generates its response.
SynthID uses “generative modeling,” a class of watermarking techniques that do not affect LLM training and only modify the sampling procedure of the model. Generative watermarking techniques modify the next-token generation procedure to make subtle, context-specific changes to the generated text. These modifications create a statistical signature in the generated text while maintaining its quality.
A classifier model is then trained to detect the statistical signature of the watermark to determine whether a response was generated by the model or not. A key benefit of this technique is that detecting the watermark is computationally efficient and does not require access to the underlying LLM.
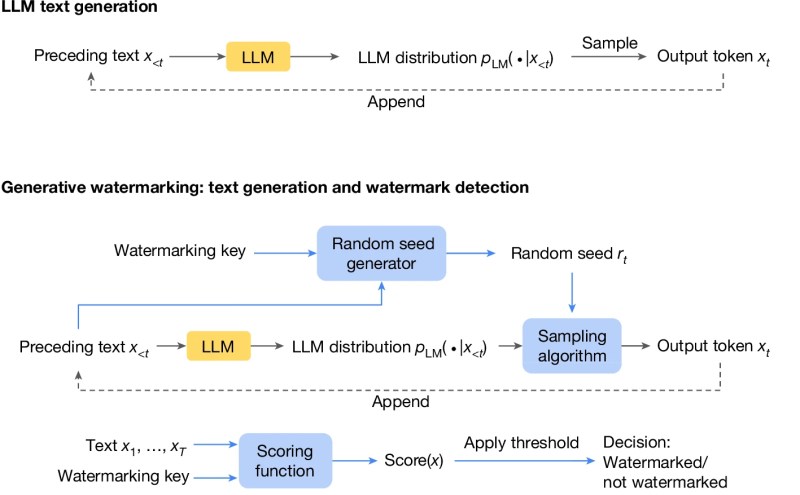
SynthID Text builds on previous work on generative watermarking and uses a novel sampling algorithm called “Tournament sampling,” which uses a multi-stage process to choose the next token when creating watermarks. The watermarking technique uses a pseudo-random function to augment the generation process of any LLM such that the watermark is imperceptible to humans but is visible to a trained classifier model. The integration into the Hugging Face library will make it easy for developers to add watermarking capabilities to existing applications.
To demonstrate the feasibility of watermarking in large-scale production systems, DeepMind researchers conducted a live experiment that assessed feedback from nearly 20 million responses generated by Gemini models. Their findings show that SynthID was able to preserve response qualities while also remaining detectable by their classifiers.
According to DeepMind, SynthID-Text has been used to watermark Gemini and Gemini Advanced.
“This serves as practical proof that generative text watermarking can be successfully implemented and scaled to real-world production systems, serving millions of users and playing an integral role in the identification and management of artificial-intelligence-generated content,” they write in their paper.
Limitations
According to the researchers, SynthID Text is robust to some post-generation transformations such as cropping pieces of text or modifying a few words in the generated text. It is also resilient to paraphrasing to some degree.
However, the technique also has a few limitations. For example, it is less effective on queries that require factual responses and doesn’t have room for modification without reducing the accuracy. They also warn that the quality of the watermark detector can drop considerably when the text is rewritten thoroughly.
“SynthID Text is not built to directly stop motivated adversaries from causing harm,” they write. “However, it can make it harder to use AI-generated content for malicious purposes, and it can be combined with other approaches to give better coverage across content types and platforms.”
Source link





