
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Large language models (LLMs) have shown promise in solving planning and reasoning tasks by searching through possible solutions. However, existing methods can be slow, computationally expensive and provide unreliable answers.
Researchers from Cornell University and IBM Research have introduced AutoToS, a new technique that combines the planning power of LLMs with the speed and accuracy of rule-based search algorithms. AutoToS eliminates the need for human intervention and significantly reduces the computational cost of solving planning problems. This makes it a promising technique for LLM applications that must reason over large solution spaces.
Thought of Search
There is a growing interest in using LLMs to handle planning problems, and researchers have developed several techniques for this purpose. The more successful techniques, such as Tree of Thoughts, use LLMs as a search algorithm that can validate solutions and propose corrections.
While these approaches have demonstrated impressive results, they face two main challenges. First, they require numerous calls to LLMs, which can be computationally expensive, especially when dealing with complex problems with thousands of possible solutions. Second, they do not guarantee that the LLM-based algorithm qualifies for “completeness” and “soundness.” Completeness ensures that if a solution exists, the algorithm will eventually find it, while soundness guarantees that any solution returned by the algorithm is valid.
Thought of Search (ToS) offers an alternative approach. ToS leverages LLMs to generate code for two key components of search algorithms: the successor function and the goal function. The successor function determines how the search algorithm explores different nodes in the search space, while the goal function checks whether the search algorithm has reached the desired state. These functions can then be used by any offline search algorithm to solve the problem. This approach is much more efficient than keeping the LLM in the loop during the search process.
“Historically, in the planning community, these search components were either manually coded for each new problem or produced automatically via translation from a description in a planning language such as PDDL, which in turn was either manually coded or learned from data,” Michael Katz, principal research staff member at IBM Research, told VentureBeat. “We proposed to use the large language models to generate the code for the search components from the textual description of the planning problem.”
The original ToS technique showed impressive progress in addressing the soundness and completeness requirements of search algorithms. However, it required a human expert to provide feedback on the generated code and help the model refine its output. This manual review was a bottleneck that reduced the speed of the algorithm.
Automating ToS
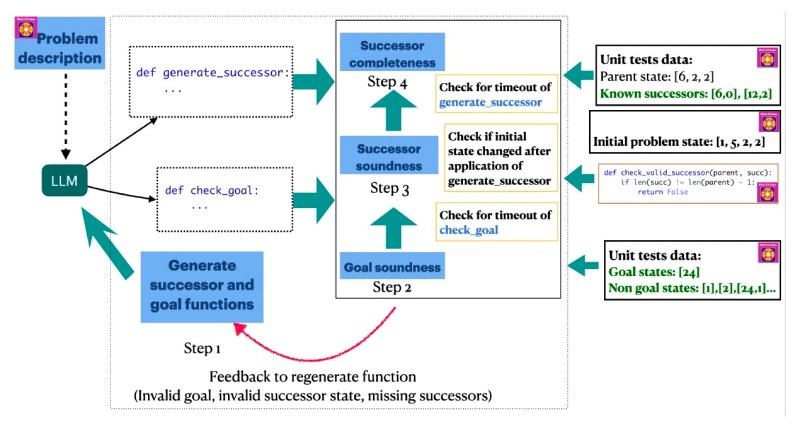
“In [ToS], we assumed a human expert in the loop, who could check the code and feedback the model on possible issues with the generated code, to produce a better version of the search components,” Katz said. “We felt that in order to automate the process of solving the planning problems provided in a natural language, the first step must be to take the human out of that loop.”
AutoToS automates the feedback and exception handling process using unit tests and debugging statements, combined with few-shot and chain-of-thought (CoT) prompting techniques.
AutoToS works in multiple steps. First, it provides the LLM with the problem description and prompts it to generate code for the successor and goal functions. Next, it runs unit tests on the goal function and provides feedback to the model if it fails. The model then uses this feedback to correct its code. Once the goal function passes the tests, the algorithm runs a limited breadth-first search to check if the functions are sound and complete. This process is repeated until the generated functions pass all the tests.
Finally, the validated functions are plugged into a classic search algorithm to perform the full search efficiently.
AutoToS in action
The researchers evaluated AutoToS on several planning and reasoning tasks, including BlocksWorld, Mini Crossword and 24 Game. The 24 Game is a mathematical puzzle where you are given four integers and must use basic arithmetic operations to create a formula that equates to 24. BlocksWorld is a classic AI planning domain where the goal is to rearrange blocks stacked in towers. Mini Crosswords is a simplified crossword puzzle with a 5×5 grid.
They tested various LLMs from different families, including GPT-4o, Llama 2 and DeepSeek Coder. They used both the largest and smallest models from each family to evaluate the impact of model size on performance.
Their findings showed that with AutoToS, all models were able to identify and correct errors in their code when given feedback. The larger models generally produced correct goal functions without feedback and required only a few iterations to refine the successor function. Interestingly, GPT-4o-mini performed surprisingly well in terms of accuracy despite its small size.
“With just a few calls to the language model, we demonstrate that we can obtain the search components without any direct human-in-the-loop feedback, ensuring soundness, completeness, accuracy and nearly 100% accuracy across all models and all domains,” the researchers write.
Compared to other LLM-based planning approaches, ToS drastically reduces the number of calls to the LLM. For example, for the 24 Game dataset, which contains 1,362 puzzles, the previous approach would call GPT-4 approximately 100,000 times. AutoToS, on the other hand, needed only 2.2 calls on average to generate sound search components.
“With these components, we can use the standard BFS algorithm to solve all the 1,362 games together in under 2 seconds and get 100% accuracy, neither of which is achievable by the previous approaches,” Katz said.
AutoToS for enterprise applications
AutoToS can have direct implications for enterprise applications that require planning-based solutions. It cuts the cost of using LLMs and reduces the reliance on manual labor, enabling experts to focus on high-level planning and goal specification.
“We hope that AutoToS can help with both the development and deployment of planning-based solutions,” Katz said. “It uses the language models where needed—to come up with verifiable search components, speeding up the development process and bypassing the unnecessary involvement of these models in the deployment, avoiding the many issues with deploying large language models.”
ToS and AutoToS are examples of neuro-symbolic AI, a hybrid approach that combines the strengths of deep learning and rule-based systems to tackle complex problems. Neuro-symbolic AI is gaining traction as a promising direction for addressing some of the limitations of current AI systems.
“I don’t think that there is any doubt about the role of hybrid systems in the future of AI,” Harsha Kokel, research scientist at IBM, told VentureBeat. “The current language models can be viewed as hybrid systems since they perform a search to obtain the next tokens.”
While ToS and AutoToS show great promise, there is still room for further exploration.
“It is exciting to see how the landscape of planning in natural language evolves and how LLMs improve the integration of planning tools in decision-making workflows, opening up opportunities for intelligent agents of the future,” Kokel and Katz said. “We are interested in general questions of how the world knowledge of LLMs can help improve planning and acting in real-world environments.”
Source link





