
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Understanding user intentions based on user interface (UI) interactions is a critical challenge in creating intuitive and helpful AI applications.
In a new paper, researchers from Apple introduce UI-JEPA, an architecture that significantly reduces the computational requirements of UI understanding while maintaining high performance. UI-JEPA aims to enable lightweight, on-device UI understanding, paving the way for more responsive and privacy-preserving AI assistant applications. This could fit into Apple’s broader strategy of enhancing its on-device AI.
The challenges of UI understanding
Understanding user intents from UI interactions requires processing cross-modal features, including images and natural language, to capture the temporal relationships in UI sequences.
“While advancements in Multimodal Large Language Models (MLLMs), like Anthropic Claude 3.5 Sonnet and OpenAI GPT-4 Turbo, offer pathways for personalized planning by adding personal contexts as part of the prompt to improve alignment with users, these models demand extensive computational resources, huge model sizes, and introduce high latency,” co-authors Yicheng Fu, Machine Learning Researcher interning at Apple, and Raviteja Anantha, Principal ML Scientist at Apple, told VentureBeat. “This makes them impractical for scenarios where lightweight, on-device solutions with low latency and enhanced privacy are required.”
On the other hand, current lightweight models that can analyze user intent are still too computationally intensive to run efficiently on user devices.
The JEPA architecture
UI-JEPA draws inspiration from the Joint Embedding Predictive Architecture (JEPA), a self-supervised learning approach introduced by Meta AI Chief Scientist Yann LeCun in 2022. JEPA aims to learn semantic representations by predicting masked regions in images or videos. Instead of trying to recreate every detail of the input data, JEPA focuses on learning high-level features that capture the most important parts of a scene.
JEPA significantly reduces the dimensionality of the problem, allowing smaller models to learn rich representations. Moreover, it is a self-supervised learning algorithm, which means it can be trained on large amounts of unlabeled data, eliminating the need for costly manual annotation. Meta has already released I-JEPA and V-JEPA, two implementations of the algorithm that are designed for images and video.
“Unlike generative approaches that attempt to fill in every missing detail, JEPA can discard unpredictable information,” Fu and Anantha said. “This results in improved training and sample efficiency, by a factor of 1.5x to 6x as observed in V-JEPA, which is critical given the limited availability of high-quality and labeled UI videos.”
UI-JEPA
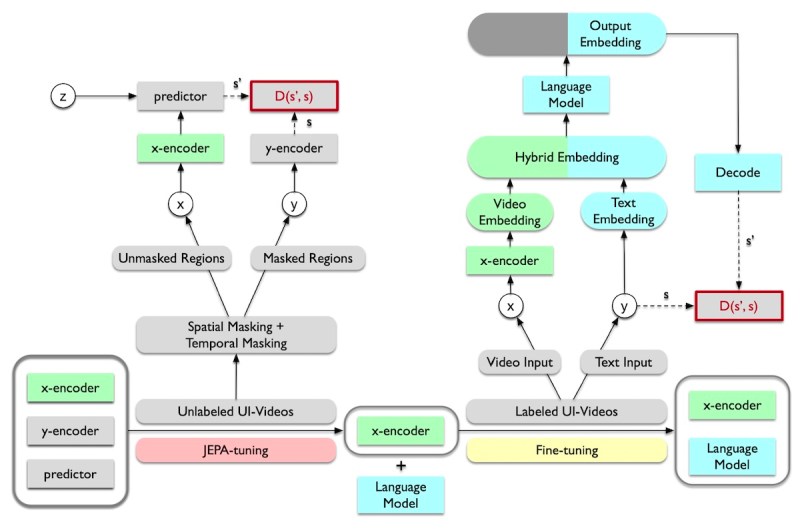
UI-JEPA builds on the strengths of JEPA and adapts it to UI understanding. The framework consists of two main components: a video transformer encoder and a decoder-only language model.
The video transformer encoder is a JEPA-based model that processes videos of UI interactions into abstract feature representations. The LM takes the video embeddings and generates a text description of the user intent. The researchers used Microsoft Phi-3, a lightweight LM with approximately 3 billion parameters, making it suitable for on-device experimentation and deployment.
This combination of a JEPA-based encoder and a lightweight LM enables UI-JEPA to achieve high performance with significantly fewer parameters and computational resources compared to state-of-the-art MLLMs.
To further advance research in UI understanding, the researchers introduced two new multimodal datasets and benchmarks: “Intent in the Wild” (IIW) and “Intent in the Tame” (IIT).
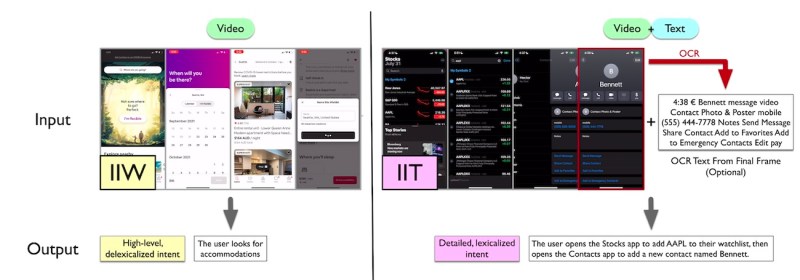
IIW captures open-ended sequences of UI actions with ambiguous user intent, such as booking a vacation rental. The dataset includes few-shot and zero-shot splits to evaluate the models’ ability to generalize to unseen tasks. IIT focuses on more common tasks with clearer intent, such as creating a reminder or calling a contact.
“We believe these datasets will contribute to the development of more powerful and lightweight MLLMs, as well as training paradigms with enhanced generalization capabilities,” the researchers write.
UI-JEPA in action
The researchers evaluated the performance of UI-JEPA on the new benchmarks, comparing it against other video encoders and private MLLMs like GPT-4 Turbo and Claude 3.5 Sonnet.
On both IIT and IIW, UI-JEPA outperformed other video encoder models in few-shot settings. It also achieved comparable performance to the much larger closed models. But at 4.4 billion parameters, it is orders of magnitude lighter than the cloud-based models. The researchers found that incorporating text extracted from the UI using optical character recognition (OCR) further enhanced UI-JEPA’s performance. In zero-shot settings, UI-JEPA lagged behind the frontier models.
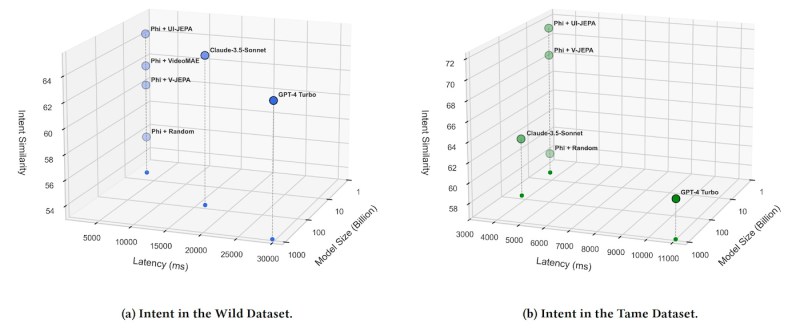
“This indicates that while UI-JEPA excels in tasks involving familiar applications, it faces challenges with unfamiliar ones,” the researchers write.
The researchers envision several potential uses for UI-JEPA models. One key application is creating automated feedback loops for AI agents, enabling them to learn continuously from interactions without human intervention. This approach can significantly reduce annotation costs and ensure user privacy.
“As these agents gather more data through UI-JEPA, they become increasingly accurate and effective in their responses,” the authors told VentureBeat. “Additionally, UI-JEPA’s capacity to process a continuous stream of onscreen contexts can significantly enrich prompts for LLM-based planners. This enhanced context helps generate more informed and nuanced plans, particularly when handling complex or implicit queries that draw on past multimodal interactions (e.g., Gaze tracking to speech interaction).”
Another promising application is integrating UI-JEPA into agentic frameworks designed to track user intent across different applications and modalities. UI-JEPA could function as the perception agent, capturing and storing user intent at various time points. When a user interacts with a digital assistant, the system can then retrieve the most relevant intent and generate the appropriate API call to fulfill the user’s request.
“UI-JEPA can enhance any AI agent framework by leveraging onscreen activity data to align more closely with user preferences and predict user actions,” Fu and Anantha said. “Combined with temporal (e.g., time of day, day of the week) and geographical (e.g., at the office, at home) information, it can infer user intent and enable a broad range of direct applications.”
UI-JEPA seems to be a good fit for Apple Intelligence, which is a suite of lightweight generative AI tools that aim to make Apple devices smarter and more productive. Given Apple’s focus on privacy, the low cost and added efficiency of UI-JEPA models can give its AI assistants an advantage over others that rely on cloud-based models.
Source link





