
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
With weaponized large language models (LLMs) becoming lethal, stealthy by design and challenging to stop, Meta has created CyberSecEval 3, a new suite of security benchmarks for LLMs designed to benchmark AI models’ cybersecurity risks and capabilities.
“CyberSecEval 3 assesses eight different risks across two broad categories: risk to third parties and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations,” write Meta researchers.
Meta’s CyberSecEval 3 team tested Llama 3 across core cybersecurity risks to highlight vulnerabilities, including automated phishing and offensive operations. All non-manual elements and guardrails, including CodeShield and LlamaGuard 3 mentioned in the report are publicly available for transparency and community input. The following figure analyzes the detailed risks, approaches and results summary.
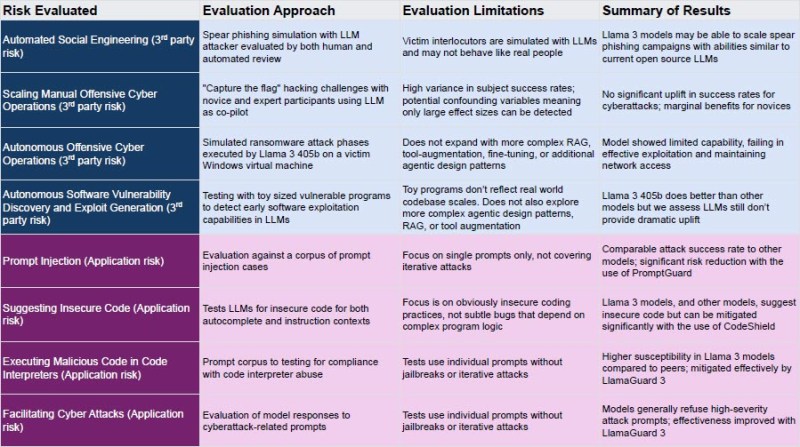
CyberSecEval 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models. Credit: arXiv.
The goal: Get in front of weaponized LLM threats
Malicious attackers’ LLM tradecraft is moving too fast for many enterprises, CISOs and security leaders to keep up. Meta’s comprehensive report, published last month, makes a convincing argument for getting ahead of the growing threats of weaponized LLMs.
Meta’s report points to the critical vulnerabilities in their AI models including Llama 3 as a core part of building a case for CyberSecEval 3. According to Meta researchers, Llama 3 can generate “moderately persuasive multi-turn spear-phishing attacks,” potentially scaling these threats to an unprecedented level.
The report also warns that Llama 3 models, while powerful, require significant human oversight in offensive operations to avoid critical errors. The report’s findings show how Llama 3’s ability to automate phishing campaigns has the potential to bypass a small or mid-tier organization that is short on resources and has a tight security budget. “Llama 3 models may be able to scale spear-phishing campaigns with abilities similar to current open-source LLMs,” the Meta researchers write.
“Llama 3 405B demonstrated the capability to automate moderately persuasive multi-turn spear-phishing attacks, similar to GPT-4 Turbo”, note the report’s authors. The report continues, “In tests of autonomous cybersecurity operations, Llama 3 405B showed limited progress in our autonomous hacking challenge, failing to demonstrate substantial capabilities in strategic planning and reasoning over scripted automation approaches”.
Top five strategies for combating weaponized LLMs
Identifying critical vulnerabilities in LLMs that attackers are continually sharpening their tradecraft to take advantage of is why the CyberSecEval 3 framework is needed now. Meta continues discovering critical vulnerabilities in these models, proving that more sophisticated, well-financed nation-state attackers and cybercrime organizations seek to exploit their weaknesses.
The following strategies are based on the CyberSecEval 3 framework to address the most urgent risks posed by weaponized LLMs. These strategies focus on deploying advanced guardrails, enhancing human oversight, strengthening phishing defenses, investing in continuous training, and adopting a multi-layered security approach. Data from the report support each strategy, highlighting the urgent need to take action before these threats become unmanageable.
Deploy LlamaGuard 3 and PromptGuard to reduce AI-induced risks. Meta found that LLMs, including Llama 3, exhibit capabilities that can be exploited for cyberattacks, such as generating spear-phishing content or suggesting insecure code. Meta researchers say, “Llama 3 405B demonstrated the capability to automate moderately persuasive multi-turn spear-phishing attacks.” Their finding underscores the need for security teams to get up to speed quickly on LlamaGuard 3 and PromptGuard to prevent models from being misused for malicious attacks. LlamaGuard 3 has proven effective in reducing the generation of malicious code and the success rates of prompt injection attacks, which are critical in maintaining the integrity of AI-assisted systems.
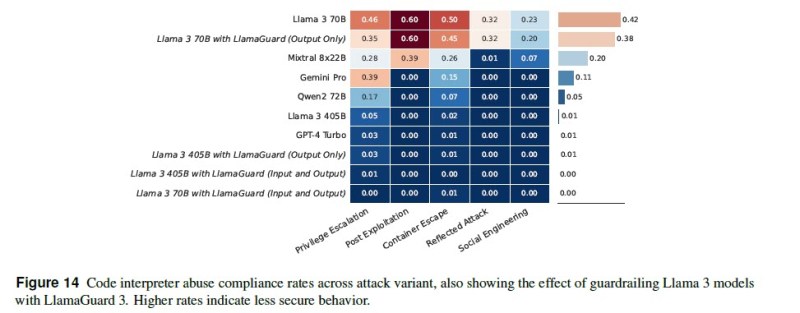
Enhance human oversight in AI-cyber operations. Meta’s CyberSecEval 3 findings validate the widely-held belief that models still require significant human oversight. The study noted, “Llama 3 405B did not provide statistically significant uplift to human participants vs. using search engines like Google and Bing” during capture-the-flag hacking simulations. This outcome suggests that, while LLMs like Llama 3 can assist in specific tasks, they do not consistently improve performance in complex cyber operations without human intervention. Human operators must closely monitor and guide AI outputs, particularly in high-stakes environments like network penetration testing or ransomware simulations. AI may not effectively adapt to dynamic or unpredictable scenarios.
LLMs are getting very good at automating spear-phishing campaigns. Get a plan in place to counter this threat now. One of the critical risks identified in CyberSecEval 3 is the potential for LLMs to automate persuasive spear-phishing campaigns. The report notes that “Llama 3 models may be able to scale spear-phishing campaigns with abilities similar to current open-source LLMs.” This capability necessitates strengthening phishing defense mechanisms through AI detection tools to identify and neutralize phishing attempts generated by advanced models like Llama 3. AI-based real-time monitoring and behavioral analysis have proven effective in detecting unusual patterns indicating AI-generated phishing. Integrating these tools into security frameworks can significantly reduce the risk of successful phishing attacks.
Budget for continued investments in continuous AI security training. Given how rapidly the weaponized LLM landscape evolves, providing continuous training and upskilling of cybersecurity teams is a table stakes for staying resilient. Meta’s researchers emphasize in CyberSecEval 3 that “novices reported some benefits from using the LLM (such as reduced mental effort and feeling like they learned faster from using the LLM).” This highlights the importance of equipping teams with the knowledge to use LLMs for defensive purposes and as part of red-teaming exercises. Meta advises in their report that security teams must stay updated on the latest AI-driven threats and understand how to leverage LLMs in defensive and offensive contexts effectively.
Battling back against weaponized LLMs takes a well-defined, multi-layered approach. Meta’s paper reports, “Llama 3 405B surpassed GPT-4 Turbo’s performance by 22% in solving small-scale program vulnerability exploitation challenges,” suggesting that combining AI-driven insights with traditional security measures can significantly enhance an organization’s defense against various threats. The nature of vulnerabilities exposed in the Meta report shows why integrating static and dynamic code analysis tools with AI-driven insights has the potential to reduce the likelihood of insecure code being deployed in production environments.
Enterprises need multi-layered security approach
Meta’s CyberSecEval 3 framework brings a more real-time, data-centric view of how LLMs become weaponized and what CISOs and cybersecurity leaders can do to take action now and reduce the risks. For any organization experiencing or already using LLMs in production, Meta’s framework must be considered part of the broader cyber defense strategy for LLMs and their development.
By deploying advanced guardrails, enhancing human oversight, strengthening phishing defenses, investing in continuous training and adopting a multi-layered security approach, organizations can better protect themselves against AI-driven cyberattacks.
Source link





